


Project Summary
In a fast-moving world, the internet plays a very vital role in connecting people. In the digital era, people like reading, writing, and sharing articles online, but what makes some articles very popular compared to others despite quality work is one of the questions I addressed in this project as well as attempting to improve article popularity prediction with unsupervised learning as compared to the poor prediction gotten from other research in this area. The dataset used in this project comes from Mashable, an online news website.
Data
This dataset summarizes a heterogeneous set of features about articles published by Mashable in two years. The goal is to predict the number of shares in social networks (popularity).
Various projects and research has been done on this data [1], [2] with people proposing several approaches to help in predicting the article’s popularity. Despite the works of various authors, the prediction accuracy is usually low something falling around 68% or less for almost all. In as much as this accuracy is low, it is understandable. The data has a lot of outliers that could be difficult for a machine learning model to map properly without resulting in overfitting.
Some Authors have proposed removed outliers from the data which has resulted in getting an improved prediction accuracy, but then removing outliers defeats the whole purpose because outliers are still part of the data (i.e they are not fake or artificial) and removing them is just to give ourself excuses.
Solution
To address the generally low prediction accuracy, I address the problem from a different perspective which effortlessly boosts the model prediction accuracy. The challenge with the data is with the outliers and attempting to force machine learning models to learn has been difficult without them resulting in overfitting. What if we could devise multiple models for the different sections of the data? In that way, we don’t have to force a single model to learn both on the normal, noise and also the outlier data. Here comes unsupervised learning with Data Clustering.
I applied an unsupervised learning algorithm for data clustering on the data so that we can group like-minded data together and then each data cluster is trained with a machine learning model that works best for that cluster. With this way, we don’t have to remove the outliers in the data, but instead have a model trained for those outliers data only. For the popularity prediction, all we have do is to first predict the cluster a sample datapoints belongs to and then based on the cluster, we pick our optimal model for that cluster to predict the article’s popularity.
An in-depth insight analysis is carried out as well to understand the factors that influence article popularity, more details can be found here.
This project is divided into two sections or I will say approaches.
- Approach 1: Learning about what makes an article popular and then applying machine learning models to predict the article’s popularity (similar to what everyone was doing). Kaggle Notebook.
- Approach 2: Using the knowledge gained and lessons learned to improve prediction accuracy. Here unsupervised learning was introduced for data clustering and then multiple models were trained on each cluster. Kaggle Notebook.
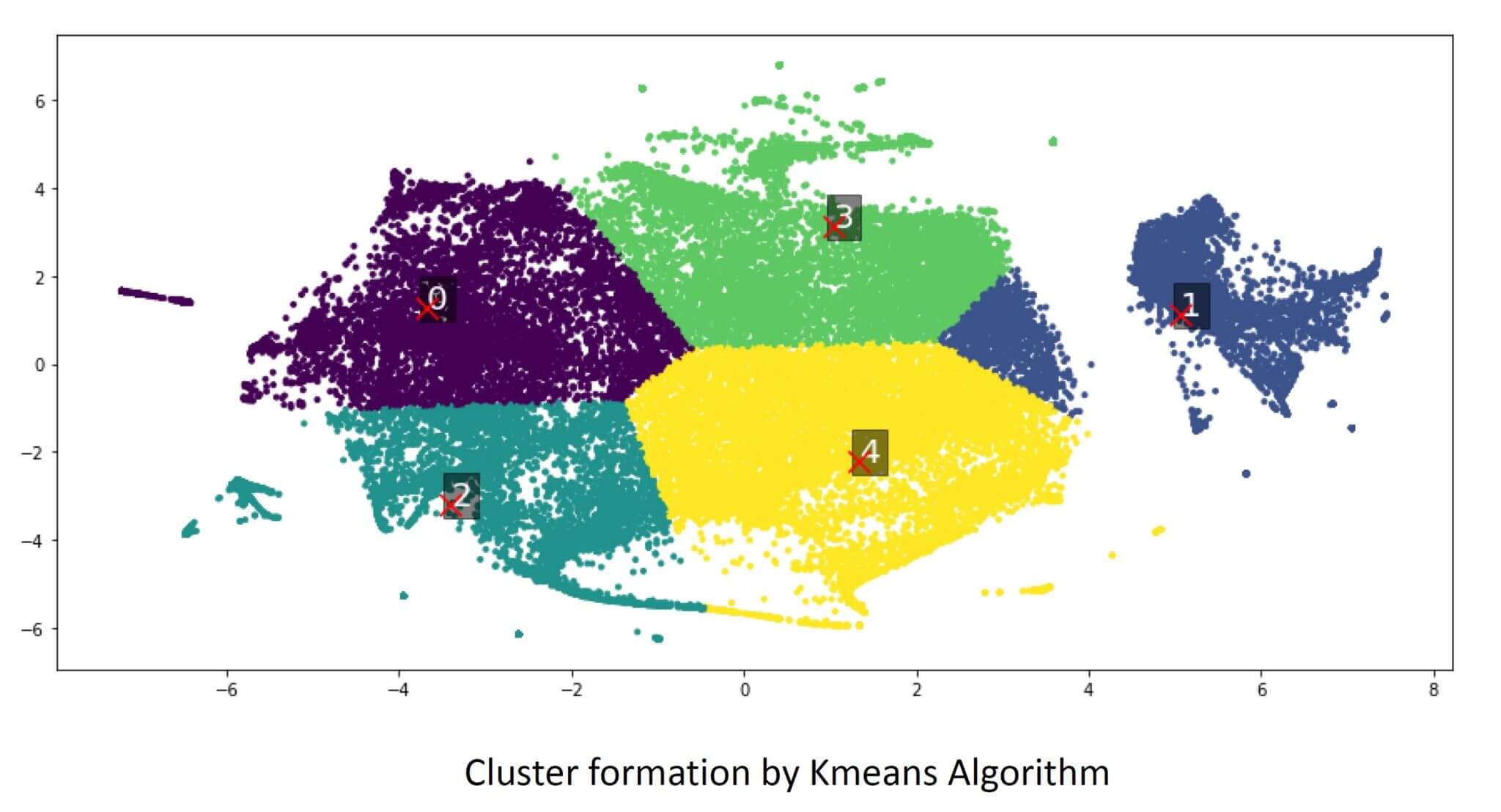
Results
After applying clustering on the data 5 clusters were formed and 3 machine learning models (KNN, Random Forest, SVM) were trained on those clusters. From the image below, cluster 5 gave the best prediction results clocking almost 75%.
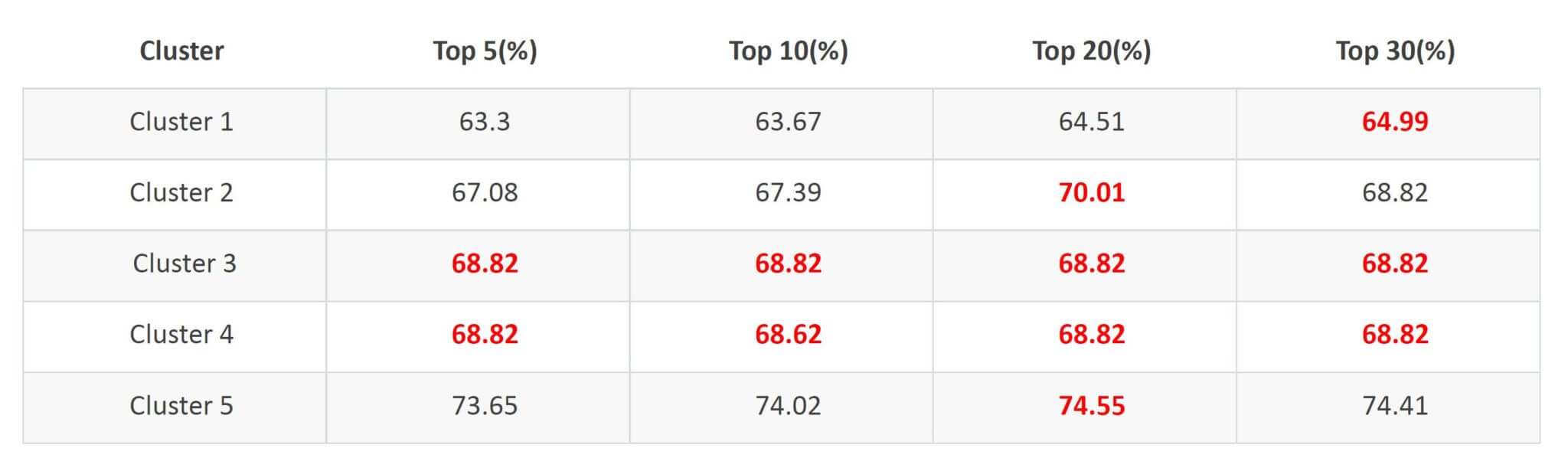
Further experiments on the clustering show that by increasing the number of clusters we can get better model predictions.
Conclusion
The clustering of the article idea was the major novelty in this project, it allowed us to be able to group similar articles and their by deploy machine learning models on those clusters as compared to using the models on the whole dataset an effort that was worth it. Generally, without the clustering, the best result from other similar works was around 68% using random forest, but by leveraging article clustering we were able to achieve a 75% accuracy and this result can even be better if we consider increasing the number of clusters used and also the feature space.
The same clustering ideology was implemented in the data channel prediction task, which gave us a maximum accuracy of 89% possible as compared to only 82% without clustering.
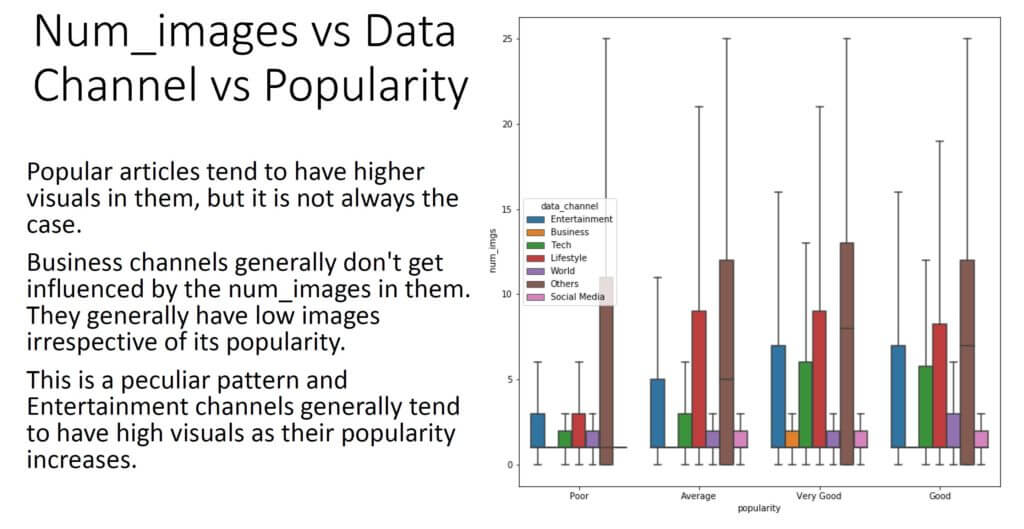
From the insight analysis carried out on the dataset, the following are some of the things we recommend improving the popularity of an article:
- The number of words in the article should be less than 1500 words. The lesser, the better.
- Article title shouldn’t be too long or too short. 6 – 17 words is the ideal number of words to have for titles.
- Articles should have a good number of images. Between 1 – 40 images are great.
- Also, having a couple of videos is nice for article popularity, but not too much. The higher, the lower the odds.
- Easy to read words helps to improve article popularity.
- The number of keywords in the metadata influences the shares to a margin. The higher the value, the better the shares chances. A value upward of 5 is recommended.
- Articles referencing popular articles have a higher chance of improving their popularity.
- Increase the number of popular unique words in the article to increase the chances of having better popularity.
- Avoid the use of longer words in the articles.
- The best popular articles are usually posted on Mondays and Wednesdays (and a bit of Tuesdays). Sundays and Saturdays (Weekends generally) are the worsts days to publish an article.
The project work can be used by publishing outlets, media houses, news sites, blogs to know what types of import attributes to focus on when writing and publishing an article.
See below link for a presentation slide for this project –
Online News Popularity – FInal – Copy
References
- F. Namous, A. Rodan, and Y. Javed, “Online News Popularity Prediction,” 2018 Fifth HCT Information Technology Trends (ITT), Dubai, United Arab Emirates, 2018, pp. 180-184, DOI: 10.1109/CTIT.2018.8649529. Source: IEEE
- Data Science Mini-project on Online News Popularity of Mashable articles by Richard Han. Source: Medium



